Preserving, Sharpening and Making Knowledge Usable
How an AI-Supported Knowledge Management Process Cushions the Skills Shortage – and Simultaneously Lays the Foundation for Reliable AI
The Silent Crisis in Our Organizations
The skills shortage is no longer an abstract future topic – it is everyday reality. Government agencies, utilities, industrial companies, and mid-sized businesses already feel how difficult it has become to fill open positions. And the situation is getting worse: Germany’s Federal Statistical Office expects that over the next 15 years, roughly 13.4 million members of the workforce will reach the statutory retirement age1 – far more than will be replaced through training, career changers, and immigration. The German Economic Institute also points out that many employees leave the labor market earlier than planned2 – meaning knowledge loss often arrives faster than workforce planning anticipates. The Institute for Employment Research (IAB) also emphasizes that even with high immigration, Germany’s labor force potential will shrink noticeably in the coming years3. The digital industry association Bitkom sees AI as the decisive lever to maintain productivity despite the shortage of skilled workers – and regularly quantifies the resulting value-creation gap in the tens of billions4.
The real problem is not just the number of people leaving, but what those people take with them:
- decades of experience with edge cases that are documented nowhere,
- informal networks (“Just call Mr. Müller, he knows”),
- tacit knowledge about processes, exceptions, and judgment calls,
- professional intuition that only develops after years of practice.
Today this knowledge resides in people’s heads, email inboxes, shared drives, notebooks, and PowerPoint slides. When the person leaves, the knowledge often leaves too – and the organization has to laboriously start over.
A Moment of Pause: Not All Knowledge Will Still Be the Right Knowledge Tomorrow
Before reflexively starting to extract every piece of knowledge from every employee, a second thought is worthwhile: Artificial intelligence is changing processes and workflows anyway.
This distinction has a long tradition: Back in the 1990s, Nonaka and Takeuchi differentiated between tacit knowledge (experience, intuition, and action-based knowledge that a person carries in their head and hands but can barely articulate in writing) and explicit knowledge (documented, formalized, shareable), describing the process of their mutual conversion as the SECI model (Socialization, Externalization, Combination, Internalization)5. More recent work extends this model to the GenAI era: Organizations that fail to systematically externalize tacit knowledge produce only fragmented digital knowledge with AI rather than a reliable foundation6.
It is important to clearly distinguish two types of knowledge:
- Domain expertise – e.g., “How does a building permit procedure work under the state building code?”, “How do I assess a structural risk?”, “How do I read a medical report?”. This knowledge remains permanently relevant. It is the substance that makes an organization capable of operating in the first place, and it will be needed even in a future heavily supported by AI – whether by humans or as the basis for AI systems that apply it.
- Process and workflow knowledge – e.g., “I print the form, have it signed three times, scan it, and file it in folder X.” This knowledge is time-bound. If we rethink a process with AI and automation, this exact workflow may be obsolete tomorrow.
The consequence for knowledge management: Not every current manual step needs to be preserved. When in doubt, it is worth asking in parallel with knowledge preservation:
“Would we build this process the same way today if we consistently factored in AI, self-service, and modern specialized applications?”
Knowledge management is therefore not just an archive but also a compass: it shows where genuine domain know-how resides (preserve!) and where we are mainly talking about ingrained routines (question and modernize!).
The Idea: Knowledge as a Guided Process – From the Mind to the Machine
This is exactly where a defined knowledge management process comes in. The basic idea is simple yet powerful:
Knowledge is no longer collected randomly but guided through a defined process – from the first idea in an expert’s mind to a machine-readable building block that an AI can reliably use.
The target vision is: “Knowledge where work happens” – reliable, findable, continuously updated, and available in a curated knowledge platform as a Single Source of Truth. Not 47 versions of the same guideline in 12 Teams channels, but one approved, maintained source that both people and AI assistants can access.
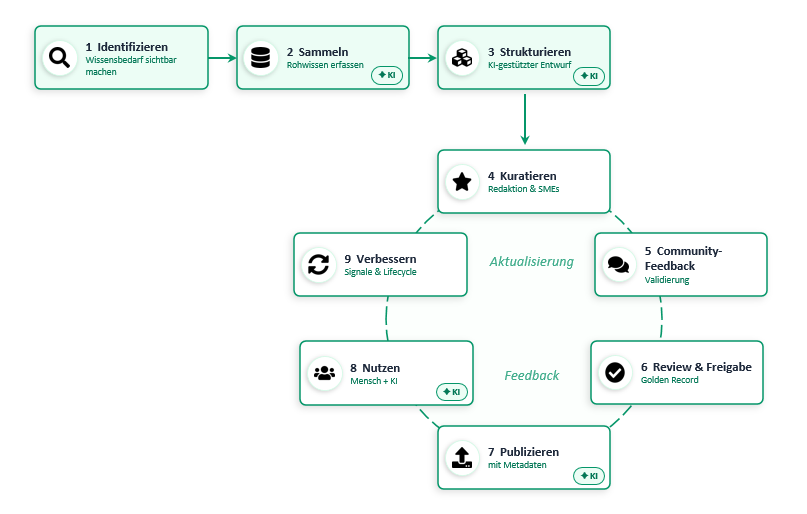
The Process at a Glance

Here is also a machine-readable version:
flowchart LR
A[1. Identify<br/>Make knowledge needs visible] --> B[2. Collect<br/>Capture raw knowledge]
B --> C[3. Structure<br/>AI-assisted draft]
C --> D[4. Curate<br/>Editorial team & SMEs]
D --> E[5. Community Feedback<br/>Validation]
E --> F[6. Review & Approval<br/>Golden Record]
F --> G[7. Publish<br/>with metadata]
G --> H[8. Use<br/>Human + AI]
H --> I[9. Improve<br/>Signals & Lifecycle]
I -.Feedback.-> D
I -.Update.-> D
classDef human fill:#D5E8F0,stroke:#2E6E8E,color:#0B2A3B;
classDef ai fill:#FDE2C4,stroke:#B25B00,color:#3B1F00;
classDef loop fill:#E8E4F3,stroke:#5B4B8A,color:#231A45;
class A,D,E,F human;
class B,C,G,H ai;
class I loop;
Color legend: Blue = human-led steps · Orange = AI-assisted steps · Purple = learning loop.
The General Workflow – Step by Step
1. Identify – Making Knowledge Needs Visible
Needs become visible continuously: from searches with no results, from recurring questions in communities, from tickets, from project retrospectives. Topics are roughly classified (domain, target audience, criticality) and prioritized. It is worthwhile to align criticality with the risk classification of the EU AI Act7: knowledge that feeds into high-risk applications (e.g., administrative decisions, medical or safety-relevant assessments) requires stronger governance from the outset than general FAQ content.
2. Collect – Making Knowledge Visible
Employees who know something (or struggle daily with an exception) can contribute their knowledge with a low barrier: as a short text, as an answer to a question, as a voice note, as an uploaded file. Synchronous formats (interview, workshop, knowledge jam) and asynchronous formats (contribution form, chat flow) complement each other.
Important: Collecting does not mean “storing everything.” Collection is targeted toward defined topic areas and use cases that truly create value for the organization. Anthropic puts it succinctly in an engineering essay: context is a finite resource – an “attention budget” that loses quality as it grows (“context rot”)8. Translated to our world: dumping everything into the knowledge platform makes it worse, not better – for humans and AI alike.
Not all knowledge can be put into writing, either. Communities of Practice, mentoring programs, and shadowing remain central formats for passing on tacit knowledge through socialization before experienced colleagues leave5 – the process complements these formats; it does not replace them.
3. Structure – Turning Raw Material into an Article Draft
The AI generates an initial draft using an agreed-upon template (how-to, FAQ, troubleshooting, decision note). It suggests titles, tags, cross-links, and potential duplicates – the subject-matter responsibility remains with the human.
4. Curate – Turning Raw Material into Reliable Knowledge
Subject-matter owners (often called “Knowledge Owners” or “editorial teams”) review, organize, and condense the contributions:
- Is the information technically correct?
- Is it up to date?
- Are there duplicates or contradictions?
- Does it need to be anonymized or generalized?
5. Community Feedback – Testing Knowledge Against Reality
Before an article becomes “official,” it goes through a professional community: colleagues from other departments, experienced practitioners, possibly external experts. They comment, correct, and supplement. Different perspectives are not “moderated away” but made visible as recommended and alternative.
6. Review & Approval – With Governance, Not Gut Feeling
A clearly designated role (e.g., department head, quality officer) approves the content. The approval is documented: who approved which version, when, and with what validity? This is the foundation for regulators, audits, and reviews to trust the result later – and for an AI to be allowed to answer based on this knowledge.
For AI usage, Microsoft recommends making approval quality measurable as well: the Azure guidelines for RAG solutions suggest evaluating answers against metrics such as Groundedness, Relevance, and Coherence, going live only when the Groundedness score is ≥ 4/5, for example9. Copilot Studio adds “Security Trimming” (only sources the user is authorized to access are returned) and mandatory citations in every answer10. Both become possible only when approval, version, and permissions are properly maintained in the knowledge management process.
7. Publish – Bringing Knowledge Where It Is Needed
Approved knowledge is placed in the knowledge platform and made visible to the right audiences: on the intranet, in SharePoint, in the specialized application, in the Teams channel – and above all prepared in a machine-readable way: with metadata, tags, validity period, target audience, sensitivity, approver, version.
Technically, “machine-readable” in the Microsoft world means specifically: the approved content is indexed (e.g., via Azure AI Search or the Microsoft Graph Semantic Index), split into chunks, vectorized as embeddings, and served via hybrid search (semantic + keyword) – this is exactly the pipeline that Microsoft 365 Copilot uses1110. The new Copilot Retrieval API now makes the same index directly accessible for custom agents and applications12.
This is the moment when “knowledge” becomes usable knowledge for AI.
8. Use – People and AI Access the Same Source
Employees find answers directly in their work context: via search, via a chat assistant, via a Copilot agent in their specialized application. Because the platform serves as the Single Source of Truth, everyone gets the same, up-to-date answer – including a source reference.
In practice, you can connect the approved knowledge base as a Declarative Agent in Microsoft 365 Copilot – with clearly scoped instructions, a connected knowledge source, and optionally even Embedded Knowledge directly in the agent package13. This turns the maintained knowledge base into a department-specific Copilot that only answers based on the content the organization has approved.
9. Improve – Closing the Loop
Every use generates signals: What questions are being asked? Which answers were helpful, which were not? Which articles are outdated? These signals flow back into the cycle – triggering new collection or curation impulses.
To keep “improve” from being a matter of gut feeling, a small KPI set is worthwhile:
- Zero-hit rate – share of searches with no results (indicator of missing knowledge).
- Article freshness – share of articles whose last review was more than X months ago.
- Reuse rate – how often an article is cited in answers.
- Groundedness score – quality of AI answers based on the knowledge base (cf. Step 6)9.
- Issue/TODO cycle time – how quickly reported gaps are closed.
This way, knowledge management becomes not a one-time campaign but a learning system.
The Deeper Reason Why This Suddenly Matters So Much in 2026: Everything is Context
What we are building here is not just an archive against demographic change. It is the production foundation for any serious AI application in the organization.
A recent contribution in software engineering research puts it precisely: “Everything is Context” (Xu et al., 2025)14. The authors argue that the central challenge of generative AI has shifted – away from fine-tuning models toward “Context Engineering.” The quality of an AI answer today depends less on the model than on what context, what knowledge, what tools, and what human decisions are made available to it and in what form.
Their proposal, inspired by the Unix principle “everything is a file,” is a file-system abstraction for context: a persistent, governed infrastructure in which heterogeneous knowledge artifacts (documents, memory, tools, human feedback) are uniformly mounted, annotated with metadata, and access-controlled. From their perspective, existing practices like prompt engineering, RAG, and tool integration remain fragmented and produce ephemeral artifacts that undermine traceability and accountability.
Translated into our language, this means:
| Paper Concept | Corresponding Element in the Knowledge Management Process |
|---|---|
| Context Constructor (Who builds the context?) | Steps 2–4: Collect, Structure, Curate |
| Context Loader (Who delivers it to the AI?) | Step 7: Publish with metadata + RAG/Index |
| Context Evaluator (Who validates?) | Steps 5–6: Community Feedback, Review, Approval |
| Human as curator, verifier, co-reasoner | Human-in-the-loop: Owner, Reviewer, Process Challenger |
| Unified metadata & access control | Content standards & classification |
| Accountable, human-centred AI co-work | Golden Record + Audit Trail |
Put differently: The knowledge management process described here is nothing other than an organizational implementation of Context Engineering. Those who curate, version, classify, and approve cleanly today are building not just a knowledge base for people tomorrow – but the substrate on which trustworthy AI agents in the organization become possible in the first place.
This gives the investment in knowledge management a double ROI:
- Today – protection against knowledge loss from the retirement wave and skills shortage.
- Tomorrow – the prerequisite for AI assistants not to hallucinate but to work on a verified, accountable foundation.
Why This Process Is So Important Right Now
- Knowledge becomes independent of individuals. When Ms. Schmidt retires, her department no longer leaves with her.
- AI gets solid ground. Large Language Models are only as good as the context they can access. A curated knowledge base is the difference between a “hallucinating assistant” and a “reliable digital colleague.”
- Processes become reflectable. Because knowledge becomes explicit, you suddenly see which workflows truly require expertise – and which exist only out of habit.
- Compliance and governance become easier. Approvals, versions, and sources are traceable – a genuine advantage in the public sector and in regulated industries.
- Regulation demands it anyway. The EU AI Act requires extensive documentation, data, and logging obligations for high-risk AI7. A clean knowledge management process delivers exactly the artifacts (approved sources, versions, audit trail) that make these obligations feasible.
What This Means for Employees
A good knowledge management process relieves the people who today are “incidental” knowledge carriers. Instead of constantly answering the same questions by email, their knowledge flows once and in a structured way into the platform. At the same time, recognition becomes visible: who curates, who contributes, who approves – that is part of the role, not an unpaid hobby.
The cultural question is important: Sharing knowledge must not be experienced as a loss of power but as a contribution to an organization that will still be capable of acting tomorrow.
From Concept to Prototype: A Sample Application Built With “Vibe Coding”
To keep the process described above from remaining a mere theory paper, I translated the idea into a small, working sample application – built in the style of so-called vibe coding: iteratively with AI support, conversation-driven, and in short loops. The code is openly available on GitHub:
Repository: https://github.com/nielsophey/pub-wissensmanagement
What the Demo Covers – and What It Deliberately Does Not
The demo is intentionally designed as a vertical slice through the first four process steps. From step 5 onward, it hands the further process over to a tool that organizations already have: source code management (GitHub or Azure DevOps). The reasoning: review, approval, publication, and learning loops have been established practices there for years – there is no point in rebuilding them in a separate knowledge platform.
flowchart LR
subgraph DEMO["Demo App (Steps 1–4)"]
direction LR
A[1. Identify<br/>Create a run] --> B[2. Collect<br/>Upload files/ZIP]
B --> C[3. Structure<br/>AI suggestion + feedback loop]
C --> D[4. Curate<br/>Wiki generation per config]
end
D ==>|"Publish: Wiki files + TODOs"| E
subgraph SCM["Source Code Management: GitHub / Azure DevOps (Steps 5–9)"]
direction LR
E[5. Community Feedback<br/>Pull Request / Review] --> F[6. Review & Approval<br/>Merge into main]
F --> G[7. Publish<br/>Wiki pages + metadata]
G --> H[8. Use<br/>Human + AI via RAG]
H --> I[9. Improve<br/>Issues / Work Items]
end
I -.Feedback.-> E
I -.Update.-> E
classDef human fill:#D5E8F0,stroke:#2E6E8E,color:#0B2A3B;
classDef ai fill:#FDE2C4,stroke:#B25B00,color:#3B1F00;
classDef loop fill:#E8E4F3,stroke:#5B4B8A,color:#231A45;
class A,E,F human;
class B,C,D,G,H ai;
class I loop;
The left half of the diagram represents the demo application. From step 5 onward, the demo hands the generated wiki files and extracted TODOs over to source code management – where review, approval, publication, and improvement are practiced as established Git/ALM workflows.
| Process Step | Location | How It Is Implemented |
|---|---|---|
| 1. Identify | Demo app (run concept) | Each “run” bundles sources around a topic area. |
| 2. Collect | Demo app (upload area) | Drag & drop of individual files or a ZIP – up to 50 files per run. |
| 3. Structure | Demo app (chat area) | AI suggests a wiki structure, the user gives feedback, the structure is iteratively refined. |
| 4. Curate / Generate | Demo app (output area) | After approval, the AI generates Markdown wiki files based on a Markdown-based configuration. |
| Publish handoff | Demo → SCM | With one click, wiki files are committed and - [ ] and TODO: markers found in Markdown are created as Issues/Work Items. |
| 5. Community Feedback | GitHub / Azure DevOps | Pull requests or wiki versioning with comments. |
| 6. Review & Approval | GitHub / Azure DevOps | Branch protection, reviewer roles, merge into main. |
| 7. Publish | GitHub Wiki / Azure DevOps Wiki | Markdown files become the readable knowledge platform. |
| 8. Use | Wiki + RAG integration | Humans read the wiki, AI assistants index the same Markdown sources. |
| 9. Improve | Issues / Work Items | Errors, gaps, and TODOs become trackable – and feed into the next run. |
Under the Hood
- Stack: Node.js / Express as a lightweight web server, three lean interfaces (run, file management, administration).
- AI integration: Azure OpenAI or Azure AI Inference (Foundry) – endpoint, deployment, and API version are managed in the admin interface; alternatively, Managed Identity without an API key.
- Configuration as Markdown: An editable
wiki-settings.mdcontrols language, target audience, structure rules (max two folder levels,index.mdper folder), quality criteria, and the convention for TODO markers. If you want to change the rules, you edit Markdown – no YAML, no UI deep dives. - Publish adapters: For GitHub, files are committed via the Contents API and TODOs are created as Issues. For Azure DevOps, wiki pages are written via the Wiki API and TODOs are created as Work Items (default type:
Task) – including a source reference to file and line. - Deployment: Locally via
npm start; for a near-production trial, Bicep templates andazdhooks are included (App Service, Application Insights, Managed Identity).
Why This Split?
Two considerations drew the line between the demo and source code management:
- Don’t reinvent the wheel. Pull requests, review workflows, version control, issue tracking, branch protection rules, and wiki rendering are already available in GitHub and Azure DevOps – production-ready, auditable, and role-based. Exactly what steps 5–9 need.
- Markdown is the common substrate. Because the demo produces pure Markdown, the published knowledge base is simultaneously human-readable (wiki in the browser) and machine-readable (RAG indexer, Copilot agents, search) – exactly the two audiences from the Everything is Context chapter.
- “Docs as Code” is not a new trend. The idea of treating documentation like code – versioned, reviewed, automatically deployed – has been established in the development community for years15. Azure DevOps even allows publishing a Markdown repository directly as a wiki16. Knowledge thus automatically inherits the quality practices of modern software teams.
Delineation: Custom Demo or Copilot Studio Right Away?
A fair question: Why build a small custom application when Microsoft already offers Copilot Studio and Declarative Agents as a no-code platform for knowledge agents1013?
The short answer: Both have their place – depending on where the friction lies.
| Concern | Suitable Tool |
|---|---|
| “We want to quickly build a Copilot agent from existing SharePoint content.” | Copilot Studio / Declarative Agent – native integration, security trimming, Azure governance. |
| “We have unstructured raw material and need an AI-assisted editorial process before content is even wiki-ready.” | Demo approach from this post – AI-assisted structuring + Git handoff. |
| “We want to fully map approval, review, and learning loops in an auditable ALM system.” | Git repo (GitHub / Azure DevOps) as the backbone, optionally connected to Copilot Studio in the usage step. |
The demo and Copilot Studio are therefore not competitors but puzzle pieces: the demo fills the gap between “raw material” and “wiki-ready Markdown”; Copilot Studio then makes the curated result conveniently usable in the M365 context.
Why This Is Relevant
- Vibe coding makes the process tangible. Instead of PowerPoint boxes, you see in just a few hours how “raw data → AI draft → curated wiki → Golden Record in Git” actually feels – and where the real friction points lie (metadata, role permissions, approval logic, merge conflicts).
- The entry point is lightweight. A knowledge platform does not have to start as a year-long project. A functional end-to-end flow helps test assumptions early, engage stakeholders, and sharpen the questions that matter for the production version (governance, scalability, integration into the existing landscape).
- The handoff to Git is the real trick. Once knowledge lives as Markdown in a versioned repository, it automatically inherits everything development organizations have built for code over the years: traceability, reviews, roles, automation, agent-friendly APIs.
The prototype obviously does not replace a production solution or governance decisions. It is deliberately intended as a discussion starter and learning object: for forking, experimenting, and evolving. Feedback, issues, and pull requests are welcome – and they end up exactly where, according to this concept, steps 5 and 9 take place.
Conclusion
The skills shortage forces organizations to turn knowledge into a guided, visible production asset – not a stroke of luck. The process outlined here – Identify → Collect → Structure → Curate → Feedback → Approve → Publish → Use → Improve – provides a robust framework for this. The key is to combine it with three attitudes:
- Consistently preserve domain knowledge, because it is the foundation of the organization.
- Deliberately question process knowledge, because otherwise AI only accelerates old workflows instead of enabling better ones.
- Treat context as infrastructure, not as a by-product – because that is precisely the foundation for any responsible AI use.
Those who think these things together are not building yet another document repository – but a learning knowledge organization that remains capable of acting even when experienced colleagues leave and new, AI-supported ways of working move in.
References and Further Reading
See Also – Further Reading by Topic
- Demographics & Labor Market: Destatis Press Release N048/20251 · IW Report on Retirement Entry2 · IAB Reports on Labor Force Potential3 · Bitkom Publications on Skills Shortage and AI4.
- Classic Knowledge Management: Nonaka & Takeuchi (1995) The Knowledge-Creating Company · Farnese et al. (2019) on the operationalization of the SECI model5.
- GenAI & Tacit Knowledge: Uchihira (2026) GenAI SECI Model6.
Statistisches Bundesamt (Destatis) (2025). 13.4 million members of the workforce will reach the statutory retirement age in the next 15 years. Press release N048, 03.09.2025. https://www.destatis.de/DE/Presse/Pressemitteilungen/2025/08/PD25_N048_13.html ↩︎ ↩︎
Hammermann, A., Pimpertz, J., & Stettes, O. (2024). Employment shortly before and after retirement. IW-Gutachten, Institut der deutschen Wirtschaft Köln. https://www.iwkoeln.de/studien/andrea-hammermann-jochen-pimpertz-oliver-stettes-beschaeftigung-kurz-vor-und-nach-dem-renteneintritt.html ↩︎ ↩︎
Institut für Arbeitsmarkt- und Berufsforschung (IAB). Projections on skilled labor demand and labor force potential in Germany. Ongoing report series. https://www.iab.de/ ↩︎ ↩︎
Bitkom e. V. Studies and press releases on the skills shortage and AI adoption in Germany. https://www.bitkom.org/Presse ↩︎ ↩︎
Farnese, M. L., Barbieri, B., Chirumbolo, A., & Patriotta, G. (2019). Managing Knowledge in Organizations: A Nonaka’s SECI Model Operationalization. Frontiers in Psychology, 10, 2730. https://pmc.ncbi.nlm.nih.gov/articles/PMC6914727/ (Based on: Nonaka, I., & Takeuchi, H. (1995). The Knowledge-Creating Company. Oxford University Press.) ↩︎ ↩︎ ↩︎
Uchihira, N. (2026). Tacit Knowledge Management with Generative AI: The GenAI SECI Model. arXiv:2603.21866. https://arxiv.org/abs/2603.21866 ↩︎ ↩︎
European Union (2024). Regulation (EU) 2024/1689 of the European Parliament and of the Council (“AI Act”). Official Journal of the EU. https://eur-lex.europa.eu/legal-content/DE/TXT/?uri=OJ:L_202401689 · Consolidated view: https://artificialintelligenceact.eu/ ↩︎ ↩︎
Anthropic (2025). Effective context engineering for AI agents. Anthropic Engineering Blog, September 29, 2025. https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents ↩︎
Microsoft Learn. Design and develop a RAG solution. Azure Architecture Center. https://learn.microsoft.com/azure/architecture/ai-ml/guide/rag/rag-solution-design-and-evaluation-guide ↩︎ ↩︎
Microsoft Learn. Enhance AI responses with Retrieval Augmented Generation (Copilot Studio). https://learn.microsoft.com/microsoft-copilot-studio/guidance/retrieval-augmented-generation ↩︎ ↩︎ ↩︎
Mei, L., Yao, J., Ge, Y. et al. (2025). A Survey of Context Engineering for Large Language Models. arXiv:2507.13334. https://arxiv.org/abs/2507.13334 ↩︎
Redmond, T. (2026). Use the Copilot Retrieval API to Run Microsoft 365 Searches. Office 365 for IT Pros Blog, 14.04.2026. https://office365itpros.com/2026/04/14/copilot-retrieval-api/ ↩︎
Microsoft Learn / M365 Agents Toolkit. Declarative agents for Microsoft 365 Copilot – overview. https://learn.microsoft.com/microsoft-365-copilot/extensibility/overview-declarative-agent ↩︎ ↩︎
Xu, X., Mao, R., Bai, Q., Gu, X., Li, Y., & Zhu, L. (2025). Everything is Context: Agentic File System Abstraction for Context Engineering. arXiv:2512.05470 [cs.SE]. https://arxiv.org/abs/2512.05470 · DOI: https://doi.org/10.48550/arXiv.2512.05470 ↩︎
Write the Docs Community. Docs as Code. https://www.writethedocs.org/guide/docs-as-code/ ↩︎
Microsoft Learn. Publish a Git Repository to a Team Wiki (Azure DevOps). https://learn.microsoft.com/azure/devops/project/wiki/publish-repo-to-wiki ↩︎