Wissen bewahren, schärfen, nutzbar machen
Wie ein KI-gestützter Wissensmanagementprozess den Fachkräftemangel abfedert – und nebenbei die Grundlage für verlässliche KI schafft
Die stille Krise in unseren Organisationen
Der Fachkräftemangel ist längst kein abstraktes Zukunftsthema mehr – er ist Alltag. Behörden, Versorger, Industriebetriebe und der Mittelstand spüren heute schon, wie schwer es geworden ist, offene Stellen zu besetzen. Und die Lage verschärft sich: Das Statistische Bundesamt rechnet damit, dass in den nächsten 15 Jahren rund 13,4 Millionen Erwerbspersonen in Deutschland das gesetzliche Rentenalter erreichen1 – deutlich mehr, als über Ausbildung, Quereinstieg und Zuwanderung nachrücken werden. Das Institut der deutschen Wirtschaft weist zudem darauf hin, dass viele Beschäftigte früher als geplant aus dem Arbeitsmarkt ausscheiden2 – der Wissensverlust kommt also oft schneller, als die Personalplanung vermuten lässt. Auch das Institut für Arbeitsmarkt- und Berufsforschung (IAB) betont: Selbst bei hoher Zuwanderung schrumpft das Erwerbspersonenpotenzial in Deutschland in den kommenden Jahren spürbar3. Der Digitalverband Bitkom sieht genau deshalb in KI den entscheidenden Hebel, um Produktivität trotz fehlender Fachkräfte zu halten – und beziffert die resultierende Wertschöpfungslücke regelmäßig im zweistelligen Milliardenbereich4.
Das eigentliche Problem ist dabei nicht nur die Zahl der Köpfe, sondern was diese Köpfe mit sich nehmen:
- jahrzehntelange Erfahrung mit Sonderfällen, die nirgendwo dokumentiert sind,
- informelle Netzwerke („Ruf mal den Herrn Müller an, der weiß Bescheid"),
- stilles Wissen über Abläufe, Ausnahmen und Bewertungsspielräume,
- fachliche Intuition, die sich erst nach Jahren entwickelt.
Dieses Wissen liegt heute in Köpfen, Mail-Postfächern, geteilten Laufwerken, Notizbüchern und PowerPoint-Folien. Wenn die Person geht, geht oft auch das Wissen – und die Organisation beginnt mühsam von vorn.
Kurz innehalten: Nicht jedes Wissen ist morgen noch das richtige Wissen
Bevor man jetzt reflexartig beginnt, alles Wissen aller Mitarbeitenden abzusaugen, lohnt ein zweiter Gedanke: Künstliche Intelligenz verändert Prozesse und Abläufe ohnehin.
Diese Unterscheidung hat Tradition: Schon Nonaka und Takeuchi haben in den 1990er-Jahren zwischen implizitem Wissen (engl. tacit knowledge – also dem Erfahrungs-, Intuitions- und Handlungswissen, das eine Person im Kopf und in den Händen trägt, aber nur schwer verschriftlichen kann) und explizitem Wissen (dokumentiert, formalisiert, teilbar) differenziert und den Prozess ihrer wechselseitigen Überführung als SECI-Modell (Sozialisierung, Externalisierung, Kombination, Internalisierung) beschrieben5. Neuere Arbeiten übertragen dieses Modell auf die GenAI-Ära: Wer implizites Wissen in Organisationen nicht systematisch externalisiert, erzeugt mit KI nur fragmentiertes digitales Wissen statt einer belastbaren Grundlage6.
Es ist wichtig, dabei zwei Arten von Wissen sauber zu unterscheiden:
- Fachliches Domänenwissen – z. B. „Wie funktioniert ein Baugenehmigungsverfahren nach Landesbauordnung?", „Wie bewerte ich ein statisches Risiko?", „Wie lese ich einen medizinischen Befund?". Dieses Wissen bleibt dauerhaft relevant. Es ist die Substanz, die eine Organisation überhaupt arbeitsfähig macht, und es wird auch in einer stark von KI unterstützten Zukunft gebraucht – sei es durch Menschen, sei es als Grundlage für KI-Systeme, die es anwenden.
- Prozess- und Ablaufwissen – z. B. „Ich drucke das Formular, lasse es drei Mal unterschreiben, scanne es ein und lege es in Ordner X ab." Dieses Wissen ist zeitgebunden. Wenn wir einen Prozess mit KI und Automatisierung neu denken, kann genau dieser Ablauf morgen überflüssig sein.
Die Konsequenz für das Wissensmanagement: Nicht jeder heutige Handgriff muss konserviert werden. Im Zweifel lohnt es sich, parallel zur Wissenssicherung zu fragen:
„Würden wir diesen Prozess heute noch einmal genauso bauen, wenn wir KI, Self-Service und moderne Fachverfahren konsequent mitdenken?"
Wissensmanagement ist damit nicht nur Archiv, sondern auch Kompass: Es zeigt, wo echtes Domänen-Know-how liegt (bewahren!) und wo wir vor allem über eingeschliffene Abläufe sprechen (hinterfragen und modernisieren!).
Die Idee: Wissen als geführter Prozess – vom Kopf bis zur Maschine
Genau hier setzt ein definierter Wissensmanagementprozess an. Die Grundidee ist einfach, aber kraftvoll:
Wissen wird nicht mehr zufällig gesammelt, sondern durch einen definierten Prozess geführt – von der ersten Idee im Kopf einer Expertin bis zum maschinenlesbaren Baustein, den eine KI zuverlässig nutzen kann.
Das Zielbild lautet: „Wissen dort, wo gearbeitet wird" – verlässlich, auffindbar, kontinuierlich aktualisiert und in einer kuratierten Wissensplattform als Single Source of Truth verfügbar. Nicht 47 Versionen derselben Richtlinie in 12 Teams-Kanälen, sondern eine freigegebene, gepflegte Quelle, auf die Menschen und KI-Assistenten gleichermaßen zugreifen.
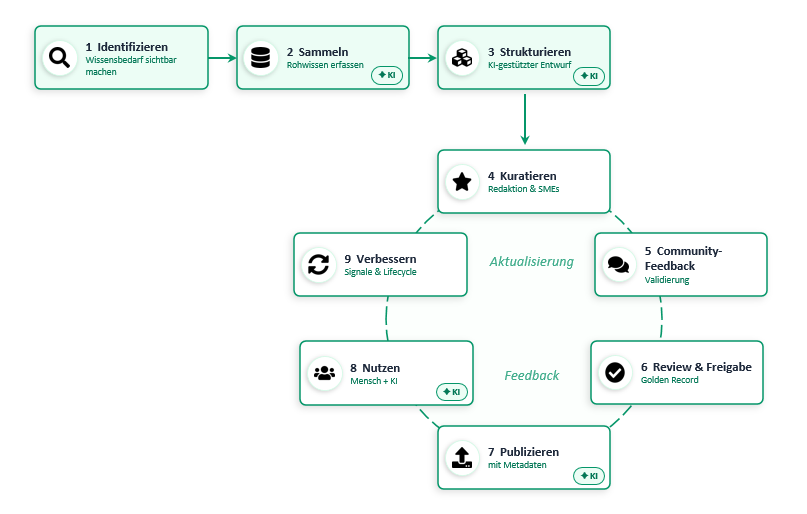
Der Prozess im Überblick

Hier auch noch mal als maschienenlesbare Variante:
flowchart LR
A[1. Identifizieren<br/>Wissensbedarf sichtbar machen] --> B[2. Sammeln<br/>Rohwissen erfassen]
B --> C[3. Strukturieren<br/>KI-gestützter Entwurf]
C --> D[4. Kuratieren<br/>Redaktion & SMEs]
D --> E[5. Community-Feedback<br/>Validierung]
E --> F[6. Review & Freigabe<br/>Golden Record]
F --> G[7. Publizieren<br/>mit Metadaten]
G --> H[8. Nutzen<br/>Mensch + KI]
H --> I[9. Verbessern<br/>Signale & Lifecycle]
I -.Feedback.-> D
I -.Aktualisierung.-> D
classDef human fill:#D5E8F0,stroke:#2E6E8E,color:#0B2A3B;
classDef ai fill:#FDE2C4,stroke:#B25B00,color:#3B1F00;
classDef loop fill:#E8E4F3,stroke:#5B4B8A,color:#231A45;
class A,D,E,F human;
class B,C,G,H ai;
class I loop;
Farblegende: Blau = menschlich geführte Schritte · Orange = KI-unterstützte Schritte · Lila = Lernschleife.
Der grundsätzliche Ablauf – Schritt für Schritt
1. Identifizieren – Wissensbedarf sichtbar machen
Bedarfe werden kontinuierlich sichtbar: aus Suchanfragen ohne Treffer, aus wiederkehrenden Fragen in Communities, aus Tickets, aus Projekt-Retrospektiven. Themen werden grob klassifiziert (Domäne, Zielgruppe, Kritikalität) und priorisiert. Dabei lohnt es sich, die Kritikalität an der Risikoklassifizierung des EU AI Act auszurichten7: Wissen, das in Hochrisiko-Anwendungen einfließt (z. B. Verwaltungsentscheidungen, medizinische oder sicherheitsrelevante Bewertungen), braucht von Anfang an stärkere Governance als allgemeine FAQ-Inhalte.
2. Sammeln – Wissen sichtbar machen
Mitarbeitende, die etwas wissen (oder täglich mit einer Ausnahme kämpfen), können ihr Wissen niedrigschwellig einkippen: als kurzen Text, als Antwort auf eine Frage, als Sprachnotiz, als hochgeladene Datei. Synchrone Formate (Interview, Workshop, Knowledge Jam) und asynchrone Formate (Beitragsformular, Chat-Flow) ergänzen sich.
Wichtig: Sammeln heißt nicht „alles speichern". Gesammelt wird gezielt zu definierten Themenfeldern und Use Cases, die für die Organisation wirklich Wert haben. Anthropic bringt es in einem Engineering-Essay auf den Punkt: Kontext ist eine endliche Ressource – ein „attention budget", das mit zunehmender Länge an Qualität verliert („context rot")8. Übersetzt in unsere Welt: Wer alles in die Wissensplattform schüttet, macht sie schlechter, nicht besser – für Menschen wie für KI.
Nicht alles Wissen lässt sich zudem verschriftlichen. Communities of Practice, Mentoring-Programme und Shadowing bleiben zentrale Formate, um implizites Wissen vor dem Ausscheiden erfahrener Kolleg:innen noch durch Sozialisierung weiterzugeben5 – der Prozess flankiert diese Formate, ersetzt sie nicht.
3. Strukturieren – aus Rohmaterial wird ein Artikelentwurf
Die KI erzeugt einen ersten Entwurf in einem vereinbarten Template (How-to, FAQ, Troubleshooting, Entscheidungsnotiz). Sie schlägt Titel, Tags, Querverlinkungen und mögliche Dubletten vor – die fachliche Verantwortung bleibt beim Menschen.
4. Kuratieren – aus Rohmaterial wird belastbares Wissen
Fachlich verantwortliche Personen (oft „Knowledge Owner" oder „Fachredaktionen") prüfen, ordnen und verdichten die Beiträge:
- Passt die Information fachlich?
- Ist sie aktuell?
- Gibt es Dubletten oder Widersprüche?
- Muss sie anonymisiert oder generalisiert werden?
5. Community-Feedback – Wissen gegen die Realität prüfen
Bevor ein Artikel „offiziell" wird, geht er durch eine fachliche Community: Kolleg:innen aus anderen Bereichen, erfahrene Anwender:innen, ggf. externe Expert:innen. Sie kommentieren, korrigieren, ergänzen. Unterschiedliche Sichtweisen werden nicht „wegmoderiert", sondern als empfohlen und alternativ sichtbar gemacht.
6. Review & Freigabe – mit Governance statt mit Bauchgefühl
Eine klar benannte Rolle (z. B. Fachbereichsleitung, Qualitätsverantwortliche) gibt frei. Die Freigabe ist dokumentiert: Wer hat wann welche Version freigegeben, mit welcher Gültigkeit? Das ist die Grundlage dafür, dass später auch Aufsichtsbehörden, Audits und Revisionen dem Ergebnis vertrauen können – und dass eine KI auf Basis dieses Wissens antworten darf.
Für die KI-Nutzung empfiehlt Microsoft, Freigabequalität auch messbar zu machen: Die Azure-Leitlinien für RAG-Lösungen schlagen vor, Antworten gegen Metriken wie Groundedness, Relevanz und Kohärenz zu evaluieren und z. B. erst ab einem Groundedness-Score ≥ 4/5 produktiv zu gehen9. Copilot Studio ergänzt dazu „Security Trimming" (nur zugriffsberechtigte Quellen werden geliefert) und Pflicht-Zitate in jeder Antwort10. Beides wird erst möglich, wenn im Wissensmanagement Freigabe, Version und Berechtigung sauber gepflegt sind.
7. Publizieren – Wissen dorthin bringen, wo es gebraucht wird
Freigegebenes Wissen wird in die Wissensplattform eingestellt und für die richtigen Zielgruppen sichtbar gemacht: im Intranet, in SharePoint, im Fachverfahren, im Teams-Kanal – und vor allem maschinenlesbar aufbereitet: mit Metadaten, Tags, Gültigkeitszeitraum, Zielgruppe, Sensitivität, Freigeber, Version.
Technisch heißt „maschinenlesbar" in der Microsoft-Welt konkret: die freigegebenen Inhalte werden indiziert (etwa über Azure AI Search oder den Microsoft Graph Semantic Index), in Chunks zerlegt, als Embeddings vektorisiert und per Hybrid-Suche (semantisch + Stichwort) bereitgestellt – in genau dieser Pipeline arbeitet auch Microsoft 365 Copilot1110. Die neue Copilot Retrieval API macht denselben Index inzwischen direkt für eigene Agenten und Anwendungen zugänglich12.
Das ist der Moment, in dem aus „Wissen" nutzbares Wissen für KI wird.
8. Nutzen – Menschen und KI greifen auf dieselbe Quelle zu
Mitarbeitende finden Antworten direkt in ihrem Arbeitskontext: über eine Suche, über einen Chat-Assistenten, über einen Copilot-Agenten im Fachverfahren. Weil die Plattform als Single Source of Truth dient, bekommt jede:r dieselbe, aktuelle Antwort – inklusive Quellenverweis.
Praktisch kann man die freigegebene Wissensbasis z. B. als Declarative Agent in Microsoft 365 Copilot anbinden – mit klar umrissenen Instruktionen, angebundener Wissensquelle und optional sogar Embedded Knowledge direkt im Agenten-Paket13. So wird aus der gepflegten Wissensbasis ein Fachbereichs-Copilot, der nur auf den Inhalten antwortet, die die Organisation freigegeben hat.
9. Verbessern – der Kreislauf schließt sich
Jede Nutzung erzeugt Signale: Welche Fragen werden gestellt? Welche Antworten waren hilfreich, welche nicht? Welche Artikel sind veraltet? Diese Signale fließen in den Kreislauf zurück – und lösen neue Sammel- oder Kuratierungsimpulse aus.
Damit „verbessern" nicht Bauchgefühl bleibt, lohnt sich ein kleines KPI-Set:
- Zero-Hit-Quote – Anteil Suchen ohne Treffer (Indikator für fehlendes Wissen).
- Artikel-Frische – Anteil Artikel, deren letzte Überprüfung länger als X Monate zurückliegt.
- Reuse-Rate – wie häufig ein Artikel in Antworten zitiert wird.
- Groundedness-Score – Qualität der KI-Antworten auf Basis der Wissensbasis (vgl. Schritt 6)9.
- Issue-/TODO-Durchlaufzeit – wie schnell gemeldete Lücken geschlossen werden.
So wird Wissensmanagement keine einmalige Kampagne, sondern ein lernendes System.
Der tiefere Grund, warum das 2026 plötzlich so wichtig wird: Everything is Context
Was wir hier bauen, ist nicht nur ein Archiv gegen den demografischen Wandel. Es ist die Produktionsgrundlage für jede ernstzunehmende KI-Anwendung in der Organisation.
Ein aktueller Beitrag in der Software-Engineering-Forschung bringt das auf den Punkt: „Everything is Context" (Xu et al., 2025)14. Die Autor:innen argumentieren, dass sich die zentrale Herausforderung generativer KI verschoben hat – weg vom Fine-Tuning der Modelle, hin zum „Context Engineering". Die Qualität einer KI-Antwort hängt heute weniger am Modell als daran, welcher Kontext, welches Wissen, welche Werkzeuge und welche menschliche Entscheidungen ihr in welcher Form zur Verfügung stehen.
Ihr Vorschlag, inspiriert vom Unix-Grundsatz „everything is a file", ist eine Dateisystem-Abstraktion für Kontext: eine persistente, gouvernierte Infrastruktur, in der heterogene Wissensartefakte (Dokumente, Memory, Tools, menschliche Rückmeldungen) einheitlich gemountet, mit Metadaten versehen und zugriffsgesteuert werden. Bisherige Praktiken wie Prompt Engineering, RAG und Tool-Integration bleiben aus ihrer Sicht fragmentiert und erzeugen flüchtige Artefakte, die Nachvollziehbarkeit und Rechenschaft unterlaufen.
Übersetzt in unsere Sprache heißt das:
| Paper-Konzept | Entsprechung im Wissensmanagementprozess |
|---|---|
| Context Constructor (Wer baut den Kontext auf?) | Schritte 2–4: Sammeln, Strukturieren, Kuratieren |
| Context Loader (Wer liefert ihn an die KI?) | Schritt 7: Publizieren mit Metadaten + RAG/Index |
| Context Evaluator (Wer validiert?) | Schritte 5–6: Community-Feedback, Review, Freigabe |
| Mensch als curator, verifier, co-reasoner | Human-in-the-loop: Owner, Reviewer, Process Challenger |
| Einheitliche Metadaten & Access Control | Content-Standards & Klassifizierung |
| Accountable, human-centred AI co-work | Golden Record + Audit-Trail |
Anders formuliert: Der hier beschriebene Wissensmanagementprozess ist nichts anderes als eine organisatorische Umsetzung von Context Engineering. Wer heute sauber kuratiert, versioniert, klassifiziert und freigibt, baut morgen nicht nur eine Wissensbasis für Menschen – sondern das Substrat, auf dem vertrauenswürdige KI-Agenten in der Organisation überhaupt erst möglich werden.
Das gibt der Investition in Wissensmanagement einen doppelten ROI:
- Heute – Schutz vor Wissensverlust durch Ruhestandswelle und Fachkräftemangel.
- Morgen – die Voraussetzung dafür, dass KI-Assistenten nicht halluzinieren, sondern auf geprüfter, verantworteter Grundlage arbeiten.
Warum dieser Prozess gerade jetzt so wichtig ist
- Wissen wird unabhängig von Einzelpersonen. Wenn Frau Schmidt in Rente geht, geht nicht mehr ihr Fachbereich mit.
- KI bekommt Boden unter den Füßen. Large Language Models sind nur so gut wie der Kontext, auf den sie zugreifen. Ein kuratierter Wissensbestand ist der Unterschied zwischen „halluzinierender Assistent" und „belastbarem digitalen Kollegen".
- Prozesse werden reflektierbar. Weil Wissen explizit wird, sieht man plötzlich, welche Abläufe wirklich Expertise brauchen – und welche nur aus Gewohnheit existieren.
- Compliance und Governance werden leichter. Freigaben, Versionen und Quellen sind nachvollziehbar – ein echter Vorteil im öffentlichen Sektor und in regulierten Branchen.
- Regulatorik zwingt ohnehin dazu. Der EU AI Act verlangt für Hochrisiko-KI umfangreiche Dokumentations-, Daten- und Protokollpflichten7. Ein sauberer Wissensmanagementprozess liefert genau die Artefakte (freigegebene Quellen, Versionen, Audit-Trail), die diese Pflichten erfüllbar machen.
Was das für Mitarbeitende heißt
Ein guter Wissensmanagementprozess entlastet die Menschen, die heute „nebenbei" Wissensträger sind. Statt ständig dieselben Fragen per Mail zu beantworten, fließt ihr Wissen einmalig und strukturiert in die Plattform. Gleichzeitig wird Anerkennung sichtbar: Wer kuratiert, wer Beiträge leistet, wer freigibt – das ist Teil der Rolle und kein unbezahltes Hobby.
Wichtig ist die Kulturfrage: Wissen zu teilen darf nicht als Machtverlust erlebt werden, sondern als Beitrag zu einer Organisation, die morgen noch handlungsfähig ist.
Vom Konzept zum Prototyp: eine Beispielanwendung aus dem „Vibe-Coding"
Um den oben beschriebenen Prozess nicht nur als Theoriepapier stehen zu lassen, habe ich die Idee in eine kleine, lauffähige Beispielanwendung übersetzt – entstanden im Stil des sogenannten Vibe-Codings: mit KI-Unterstützung iterativ, konversationsgetrieben und in kurzen Schleifen gebaut. Der Code liegt offen auf GitHub:
Repository: https://github.com/nielsophey/pub-wissensmanagement
Was die Demo abdeckt – und was bewusst nicht
Die Demo ist bewusst als Durchstich durch die ersten vier Prozessschritte konzipiert. Ab Schritt 5 übergibt sie den weiteren Prozess an ein Werkzeug, das Organisationen ohnehin haben: die Quellcodeverwaltung (GitHub oder Azure DevOps). Der Gedanke dahinter: Review, Freigabe, Publikation und Lernschleife sind dort seit Jahren etablierte Praktiken – es lohnt nicht, sie in einer eigenen Wissensplattform nachzubauen.
flowchart LR
subgraph DEMO["Demo-App (Schritte 1–4)"]
direction LR
A[1. Identifizieren<br/>Durchlauf anlegen] --> B[2. Sammeln<br/>Upload Dateien/ZIP]
B --> C[3. Strukturieren<br/>KI-Vorschlag + Feedback-Schleife]
C --> D[4. Kuratieren<br/>Wiki-Generierung nach Config]
end
D ==>|"Publish: Wiki-Dateien + TODOs"| E
subgraph SCM["Quellcodeverwaltung: GitHub / Azure DevOps (Schritte 5–9)"]
direction LR
E[5. Community-Feedback<br/>Pull Request / Review] --> F[6. Review & Freigabe<br/>Merge in main]
F --> G[7. Publizieren<br/>Wiki-Seiten + Metadaten]
G --> H[8. Nutzen<br/>Mensch + KI via RAG]
H --> I[9. Verbessern<br/>Issues / Work Items]
end
I -.Feedback.-> E
I -.Aktualisierung.-> E
classDef human fill:#D5E8F0,stroke:#2E6E8E,color:#0B2A3B;
classDef ai fill:#FDE2C4,stroke:#B25B00,color:#3B1F00;
classDef loop fill:#E8E4F3,stroke:#5B4B8A,color:#231A45;
class A,E,F human;
class B,C,D,G,H ai;
class I loop;
Die linke Hälfte des Diagramms bildet die Demo-Anwendung ab. Ab Schritt 5 übergibt die Demo die generierten Wiki-Dateien und die extrahierten TODOs an die Quellcodeverwaltung – dort werden Review, Freigabe, Publikation und Verbesserung als etablierte Git-/ALM-Praktiken gelebt.
| Prozessschritt | Ort | Wie umgesetzt |
|---|---|---|
| 1. Identifizieren | Demo-App (Durchlauf-Konzept) | Je „Durchlauf" bündelt man Quellen zu einem Themenfeld. |
| 2. Sammeln | Demo-App (Upload-Bereich) | Drag & Drop von einzelnen Dateien oder einem ZIP – bis zu 50 Dateien pro Durchlauf. |
| 3. Strukturieren | Demo-App (Chat-Bereich) | KI schlägt eine Wiki-Struktur vor, Nutzer:in gibt Feedback, Struktur wird iterativ verfeinert. |
| 4. Kuratieren / Generieren | Demo-App (Output-Bereich) | Nach Freigabe erzeugt die KI Markdown-Wiki-Dateien nach einer Markdown-basierten Konfiguration. |
| Publish-Übergabe | Demo → SCM | Per Klick werden Wiki-Dateien committed und in Markdown gefundene - [ ]- und TODO:-Marker als Issues/Work Items angelegt. |
| 5. Community-Feedback | GitHub / Azure DevOps | Pull Requests bzw. Wiki-Versionierung mit Kommentaren. |
| 6. Review & Freigabe | GitHub / Azure DevOps | Branch Protection, Reviewer-Rollen, Merge in main. |
| 7. Publizieren | GitHub Wiki / Azure DevOps Wiki | Markdown-Dateien werden zur lesbaren Wissensplattform. |
| 8. Nutzen | Wiki + RAG-Anbindung | Mensch liest im Wiki, KI-Assistent indexiert dieselben Markdown-Quellen. |
| 9. Verbessern | Issues / Work Items | Fehler, Lücken und TODOs werden trackbar – und fließen in den nächsten Durchlauf. |
Technisch unter der Haube
- Stack: Node.js / Express als kleiner Webserver, drei schlanke Oberflächen (Durchlauf, Datei-Management, Administration).
- KI-Anbindung: Azure OpenAI oder Azure AI Inference (Foundry) – Endpoint, Deployment und API-Version werden in der Admin-Oberfläche gepflegt; alternativ Managed Identity ohne API-Key.
- Konfiguration als Markdown: Eine bearbeitbare
wiki-settings.mdsteuert Sprache, Zielgruppe, Strukturregeln (max. zwei Ordnerebenen,index.mdje Ordner), Qualitätskriterien und die Konvention für TODO-Marker. Wer die Regeln ändern will, editiert Markdown – kein YAML, keine UI-Tiefen. - Publish-Adapter: Für GitHub werden Dateien über die Contents-API committet und TODOs als Issues angelegt. Für Azure DevOps werden Wiki-Seiten über die Wiki-API geschrieben und TODOs als Work Items (Standardtyp:
Task) erzeugt – inklusive Quellverweis auf Datei und Zeile. - Deployment: Lokal per
npm start; für eine produktionsnahe Erprobung liegen Bicep-Templates undazd-Hooks bei (App Service, Application Insights, Managed Identity).
Warum diese Aufteilung?
Zwei Überlegungen haben die Grenze zwischen Demo und Quellcodeverwaltung gezogen:
- Nicht jedes Rad neu erfinden. Pull Requests, Review-Workflows, Versionsverwaltung, Issue-Tracking, Branch-Protection-Regeln und Wiki-Rendering sind in GitHub und Azure DevOps bereits produktiv, auditierbar und rollenbasiert verfügbar. Genau das, was Schritte 5–9 brauchen.
- Markdown ist das gemeinsame Substrat. Weil die Demo reines Markdown erzeugt, ist der publizierte Wissensbestand gleichzeitig menschenlesbar (Wiki im Browser) und maschinenlesbar (RAG-Indexer, Copilot-Agenten, Suchen) – genau die zwei Zielgruppen aus Kapitel Everything is Context.
- „Docs-as-Code" ist kein neuer Trend. Die Idee, Dokumentation wie Code zu behandeln – versioniert, reviewed, automatisiert ausgeliefert – ist in der Entwicklungs-Community seit Jahren etabliert15. Azure DevOps erlaubt es sogar, ein Markdown-Repository direkt als Wiki zu veröffentlichen16. Wissen erbt damit automatisch die Qualitätspraktiken moderner Software-Teams.
Abgrenzung: Eigene Demo oder doch gleich Copilot Studio?
Eine berechtigte Frage: Warum eine eigene kleine Anwendung, wenn Microsoft mit Copilot Studio und Declarative Agents bereits eine No-Code-Plattform für Wissensagenten anbietet1013?
Die kurze Antwort: Beides hat seine Berechtigung – je nachdem, wo die Reibung liegt.
| Anliegen | Passendes Werkzeug |
|---|---|
| „Wir wollen schnell aus vorhandenen SharePoint-Inhalten einen Copilot-Agenten bauen." | Copilot Studio / Declarative Agent – native Integration, Security-Trimming, Azure-Governance. |
| „Wir haben unstrukturiertes Rohmaterial und brauchen einen KI-gestützten Redaktionsprozess, bevor Inhalte überhaupt wiki-tauglich sind." | Demo-Ansatz aus diesem Beitrag – AI-gestütztes Strukturieren + Git-Handoff. |
| „Wir wollen Freigabe, Review und Lernschleife voll in einem auditierbaren ALM-System abbilden." | Git-Repo (GitHub / Azure DevOps) als Backbone, optional angebunden an Copilot Studio im Nutzungsschritt. |
Die Demo und Copilot Studio sind damit keine Konkurrenten, sondern Puzzlestücke: Die Demo füllt die Lücke zwischen „Rohmaterial" und „wiki-reifem Markdown"; Copilot Studio macht das kuratierte Ergebnis anschließend im M365-Kontext bequem nutzbar.
Warum das relevant ist
- Vibe-Coding macht den Prozess greifbar. Statt PowerPoint-Kästchen sieht man in wenigen Stunden, wie sich „Rohdaten → KI-Entwurf → kuratiertes Wiki → Golden Record in Git" tatsächlich anfühlt – und wo im Ablauf die echten Reibungspunkte liegen (Metadaten, Rollenrechte, Freigabelogik, Merge-Konflikte).
- Der Einstieg ist leichtgewichtig. Eine Wissensplattform muss nicht als Jahresprojekt starten. Ein funktionsfähiger End-to-End-Flow hilft, Annahmen früh zu testen, Stakeholder einzubinden und die Fragen zu schärfen, die für die produktive Variante zählen (Governance, Skalierung, Integration in bestehende Landschaft).
- Die Übergabe an Git ist der eigentliche Trick. Sobald Wissen in Markdown in einem versionierten Repository liegt, erbt es automatisch alles, was Entwicklungsorganisationen seit Jahren für Code gebaut haben: Nachvollziehbarkeit, Reviews, Rollen, Automatisierung, Agenten-freundliche APIs.
Der Prototyp ersetzt natürlich keine produktive Lösung und keine Governance-Entscheidungen. Er ist bewusst als Diskussionsgrundlage und Lernobjekt gedacht: zum Forken, Ausprobieren, Weiterentwickeln. Feedback, Issues und Pull Requests sind willkommen – und landen übrigens genau da, wo laut diesem Konzept die Schritte 5 und 9 stattfinden.
Fazit
Der Fachkräftemangel zwingt Organisationen, Wissen zu einem geführten, sichtbaren Produktionsgut zu machen – nicht zu einem Glücksfall. Der hier skizzierte Prozess Identifizieren → Sammeln → Strukturieren → Kuratieren → Feedback → Freigeben → Publizieren → Nutzen → Verbessern ist dafür ein belastbarer Rahmen. Entscheidend ist, ihn mit drei Haltungen zu verbinden:
- Domänenwissen konsequent bewahren, weil es das Fundament der Organisation ist.
- Prozesswissen bewusst hinterfragen, weil KI sonst nur alte Abläufe beschleunigt, statt bessere zu ermöglichen.
- Kontext als Infrastruktur begreifen, nicht als Nebenprodukt – denn genau das ist die Grundlage für jede verantwortbare KI-Nutzung.
Wer das zusammendenkt, baut keine weitere Dokumentenablage – sondern eine lernende Wissensorganisation, die auch dann handlungsfähig bleibt, wenn erfahrene Kolleg:innen gehen und neue, KI-gestützte Arbeitsweisen einziehen.
Quellen und weiterführende Literatur
Siehe auch – weiterführende Lektüre nach Themen
- Demografie & Arbeitsmarkt: Destatis Pressemitteilung N048/20251 · IW-Gutachten zu Renteneintritt2 · IAB-Berichte zum Erwerbspersonenpotenzial3 · Bitkom-Veröffentlichungen zu Fachkräftemangel und KI4.
- Wissensmanagement-Klassik: Nonaka & Takeuchi (1995) The Knowledge-Creating Company · Farnese et al. (2019) zur Operationalisierung des SECI-Modells5.
- GenAI & implizites Wissen: Uchihira (2026) GenAI SECI Model6.
- Context Engineering: Xu et al. (2025) Everything is Context14 · Mei et al. (2025) Survey11 · Anthropic Engineering Blog zum „attention budget"8.
- Enterprise-RAG & Microsoft-Stack: Azure Architecture Center RAG-Guide9 · Copilot Studio RAG-Dokumentation10 · Declarative Agents Übersicht13 · Copilot Retrieval API12.
- Docs-as-Code & ALM-Backbone: Write the Docs Community Guide15 · Azure DevOps „Publish Repo to Wiki"16.
- Regulatorik: EU AI Act (VO 2024/1689)7.
Begleitende Beispielanwendung (Vibe-Coding-Prototyp): https://github.com/nielsophey/wissenmanagement
Statistisches Bundesamt (Destatis) (2025). 13,4 Millionen Erwerbspersonen erreichen in den nächsten 15 Jahren das gesetzliche Rentenalter. Pressemitteilung N048 vom 03.09.2025. https://www.destatis.de/DE/Presse/Pressemitteilungen/2025/08/PD25_N048_13.html ↩︎ ↩︎
Hammermann, A., Pimpertz, J., & Stettes, O. (2024). Beschäftigung kurz vor und nach dem Renteneintritt. IW-Gutachten, Institut der deutschen Wirtschaft Köln. https://www.iwkoeln.de/studien/andrea-hammermann-jochen-pimpertz-oliver-stettes-beschaeftigung-kurz-vor-und-nach-dem-renteneintritt.html ↩︎ ↩︎
Institut für Arbeitsmarkt- und Berufsforschung (IAB). Projektionen zu Fachkräftebedarf und Erwerbspersonenpotenzial in Deutschland. Laufende Berichtsreihe. https://www.iab.de/ ↩︎ ↩︎
Bitkom e. V. Studien und Pressemitteilungen zu Fachkräftemangel und KI-Einsatz in Deutschland. https://www.bitkom.org/Presse ↩︎ ↩︎
Farnese, M. L., Barbieri, B., Chirumbolo, A., & Patriotta, G. (2019). Managing Knowledge in Organizations: A Nonaka’s SECI Model Operationalization. Frontiers in Psychology, 10, 2730. https://pmc.ncbi.nlm.nih.gov/articles/PMC6914727/ (Grundlage: Nonaka, I., & Takeuchi, H. (1995). The Knowledge-Creating Company. Oxford University Press.) ↩︎ ↩︎ ↩︎
Uchihira, N. (2026). Tacit Knowledge Management with Generative AI: The GenAI SECI Model. arXiv:2603.21866. https://arxiv.org/abs/2603.21866 ↩︎ ↩︎
Europäische Union (2024). Verordnung (EU) 2024/1689 des Europäischen Parlaments und des Rates („AI Act"). Amtsblatt der EU. https://eur-lex.europa.eu/legal-content/DE/TXT/?uri=OJ:L_202401689 · Konsolidierte Sicht: https://artificialintelligenceact.eu/ ↩︎ ↩︎ ↩︎
Anthropic (2025). Effective context engineering for AI agents. Anthropic Engineering Blog, 29. September 2025. https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents ↩︎ ↩︎
Microsoft Learn. Design and develop a RAG solution. Azure Architecture Center. https://learn.microsoft.com/azure/architecture/ai-ml/guide/rag/rag-solution-design-and-evaluation-guide ↩︎ ↩︎ ↩︎
Microsoft Learn. Enhance AI responses with Retrieval Augmented Generation (Copilot Studio). https://learn.microsoft.com/microsoft-copilot-studio/guidance/retrieval-augmented-generation ↩︎ ↩︎ ↩︎ ↩︎
Mei, L., Yao, J., Ge, Y. et al. (2025). A Survey of Context Engineering for Large Language Models. arXiv:2507.13334. https://arxiv.org/abs/2507.13334 ↩︎ ↩︎
Redmond, T. (2026). Use the Copilot Retrieval API to Run Microsoft 365 Searches. Office 365 for IT Pros Blog, 14.04.2026. https://office365itpros.com/2026/04/14/copilot-retrieval-api/ ↩︎ ↩︎
Microsoft Learn / M365 Agents Toolkit. Declarative agents for Microsoft 365 Copilot – overview. https://learn.microsoft.com/microsoft-365-copilot/extensibility/overview-declarative-agent ↩︎ ↩︎ ↩︎
Xu, X., Mao, R., Bai, Q., Gu, X., Li, Y., & Zhu, L. (2025). Everything is Context: Agentic File System Abstraction for Context Engineering. arXiv:2512.05470 [cs.SE]. https://arxiv.org/abs/2512.05470 · DOI: https://doi.org/10.48550/arXiv.2512.05470 ↩︎ ↩︎
Write the Docs Community. Docs as Code. https://www.writethedocs.org/guide/docs-as-code/ ↩︎ ↩︎
Microsoft Learn. Publish a Git Repository to a Team Wiki (Azure DevOps). https://learn.microsoft.com/azure/devops/project/wiki/publish-repo-to-wiki ↩︎ ↩︎